Setting up Method 2.
Note: Basic
knowledge of GATE is assumed (loading and working with corpora and
different processing resources).
1)
Linguistic preprocessing:
For this method
the lingusitic preprocessing has to be done outside GATE.
First, run your corpus thorugh the Minipar dependency parser.
To get the best results you should preprocess your corpus as
follows:
* transform all
UpperCase to LowerCase.
* if there is a verb in
the first position and ends in "s" - remove this termination.
* split up the text so
that you have one sentence per line.
Second, transform the Minipar output in annotations readable by
GATE. A java class that does this is available here. Minipar's output format is
slightly different on different platforms so you might need to re-adapt
this file.
2)
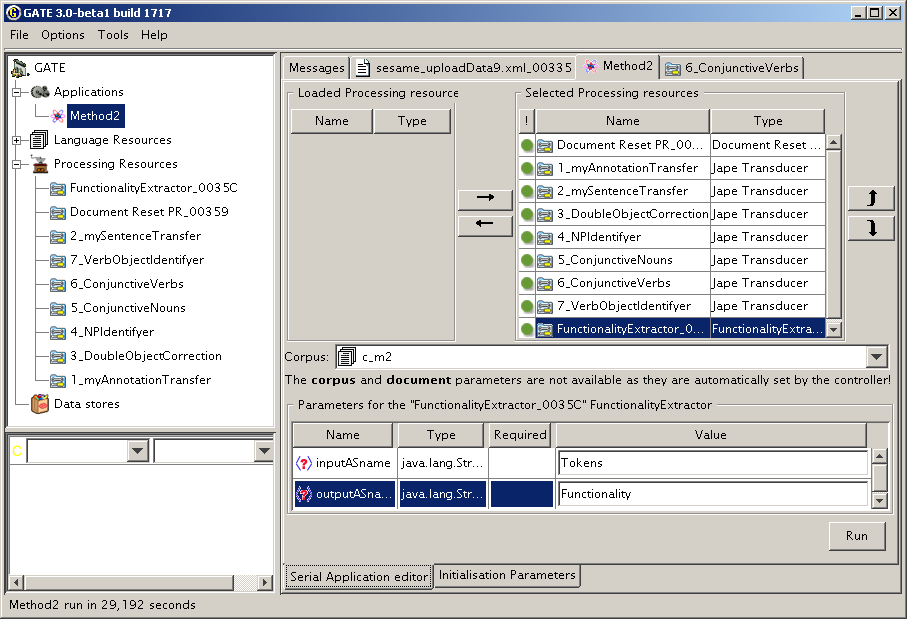
Pattern based extraction:
Then load
the following JAPE transducers one by one in this order and add them to
the pipeline.
Alternatively you can simply load main.jape which will load all the
transducers for you.
* 1_myWordTransfer (set inputASName = Original markups
and outputASName = Tokens)
* 2_mySentenceTransfer (set inputASName = Original markups
and outputASName = Tokens)
* 2_DoubleObjectCorrection (set inputASName = outputASName = Tokens)
* 3_NPIdentifyer (set inputASName = outputASName = Tokens)
* 4_ConjunctiveNouns (set inputASName = outputASName = Tokens)
* 5_ConjunctiveVerbs (set inputASName = outputASName = Tokens)
* 6_VerbObjectIdentifyer (set inputASName = outputASName = Tokens)
Note: you could
save this corpus somewhere so that you do not repeat
these steps.
3)
Ontology learning - this step is the same as for Method1